
数据类型
原始数据类型
{
"text": "九玄珠是在纵横中文网连载的一部小说,作者是龙马",
"spo_list": [
["九玄珠", "连载网站", "纵横中文网"],
["九玄珠", "作者", "龙马"]
]
}
笔者实际任务
{
"text": "2、负责oa系统建设、运营及维护",
"spo_list": [
["oa系统", "链接", "建设"],
["oa系统", "链接", "运营"],
["oa系统", "链接", "维护"]
]
}
{
"text": "2、策划并运营公司品牌及产品在线上的推广与管理",
"spo_list": [
["策划", "链接", "公司品牌"],
["运营", "链接", "公司品牌"],
["产品", "链接", "线上"],
["线上", "链接", "推广"],
["线上", "链接", "管理"]
]
}
数据输出就是三元组(s,p,o)的形式,s就是subject,即主实体,o是object,即客实体,p是predicate,实体关系,最终从主实体链接到客实体,客实体若还是另一三元组的主实体,则继续链接到客实体作为主实体的客实体,即s->o(s)->o。
样本特点
观察数据发现“一对多”的抽取+分类任务,数据有如下特点
- s和o的实体并不一定都能被切词工具切出来,因此存在切错边界的问题,所以我们采用字来做;
- 样本存在多种情况,有一个s对应多个o的情况,eg:线上推广与管理->线上推广、线上管理,也存在多个s对应一个o的情况,eg:软件开发以及调试->软件开发、软件调试;
模型设计
seq2seq解码器建模如下$P(y_1,y_2,…,y_n∣x)=P(y_1∣x)P(y_2∣x,y_1)…P(y_n∣x,y_1,y_2,…,y_{n−1})$
实际预测的时候,先通过x来预测第一个单词,然后假设第一个词已知预测第二个单词,以此类推,知道结果标记出现。在三元组中参考此思路。
$P(s,p,o)=P(s)P(o∣s)P(p∣o,s)P(s,p,o)$
通过先预测s,然后传入s来预测s对应的o,在传入s,o来预测关系p,实际应用中,我们还可以把o,p的预测合并为一步。
理论上,上述模型只能抽取单一一个三元组,为了处理多个情况,我们全部使用“半指针-半标注”结构,即将softmax换成sigmoid,在DGCNN中介绍。
# copy
注1:为什么不先预测o然后再预测s及对应的p?
那是因为引入在第二步预测的时候要采样传入第一步的结果(而且只采样一个),而前面已经分析了,
多数样本的o的数目比s的数目要多,所以我们先预测s,然后传入s再预测o、p的时候,对s的采样就
很容易充分了(因为s少),反过来如果要对o进行采样就不那么容易充分(因为o可能很多)。
带着这个问题继续读下去,读者会更清楚地认识到这一点。
注2:刷到最近的arxiv论文,发现在思想上,本文的这种抽取设计与文章《Entity-Relation
Extraction as Multi-Turn Question Answering》类似。
模型结构
模型结构示意图如下
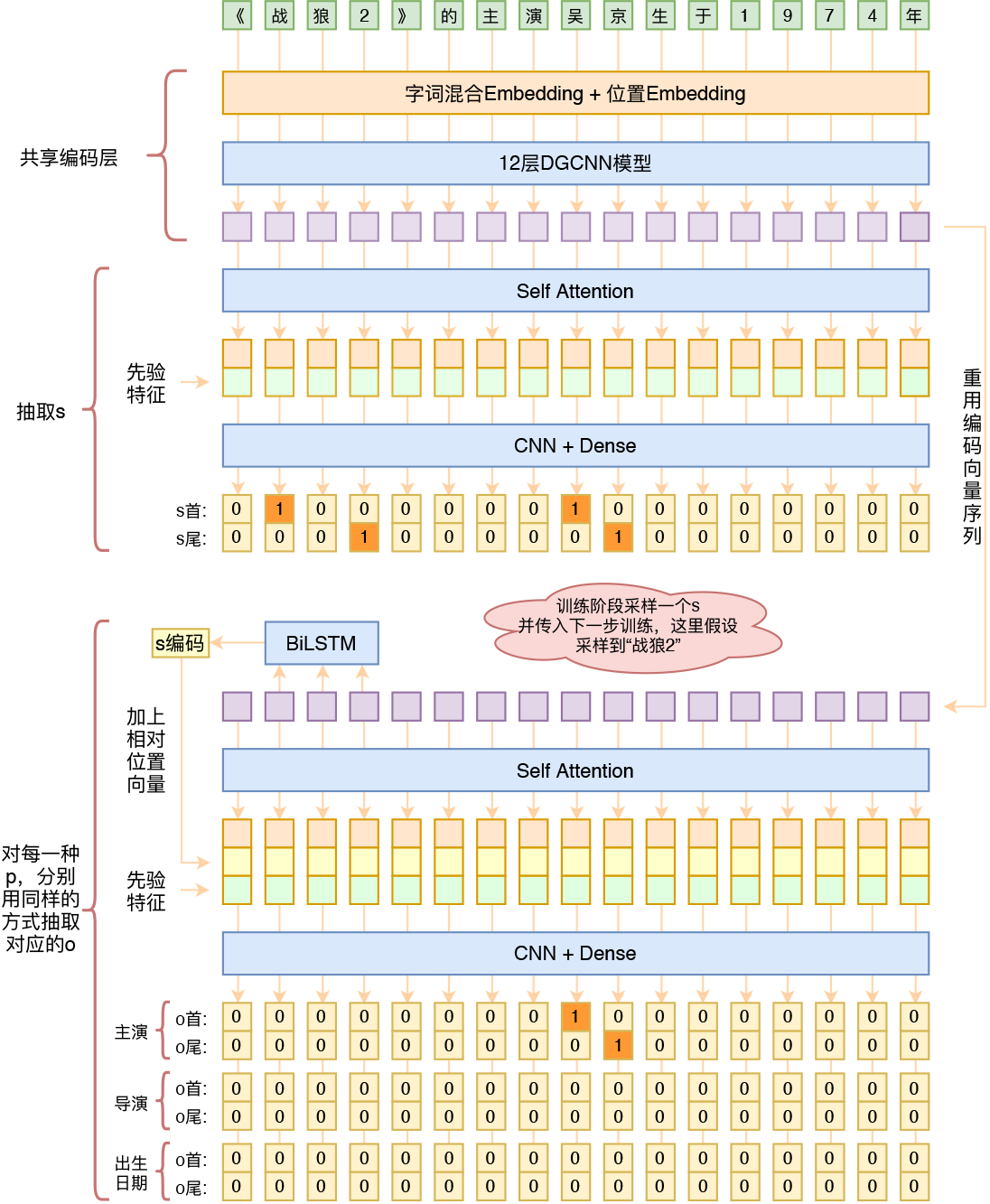
模型处理流程如下:
- 输入字id序列,然后通过字词混合Embedding得到对应的子向量序列,然后加上Position Embedding;
- 将得到的“字-词-位置Embedding”输入到12层DGCNN进行编码,得到编码后的序列(记为$H$);
- 将$H$传入一层Self Attention后,将输出结果与先验特征进行拼接(先验可加可不加);
- 将拼接后的结果传入CNN、Dense,用“半指针-半标注”结构预测s的首、尾位置;
- 训练时随机采样一个标注的s(预测时逐一遍历所有的s),然后将HHH对应此s的子序列传入到一个双向LSTM中,得到s的编码向量,然后加上相对位置的Position Embedding,得到一个与输入序列等长的向量序列;
- 将HHH传入另一层Self Attention后,将输出结果与第5步输出的向量序列、先验特征进行拼接(先验特征可加可不加,构建方式后面再详细介绍);
- 将拼接后的结果传入CNN、Dense,对于每一种p,都构建一个“半指针-半标注”结构来预测对应的o的首、尾位置,这样就同时把o、p都预测出来了。
问题一:为啥第5步只采样一个s?
1、采样一个就够了,采样多个相当于等效增大batch size;
2、采样一个比较好操作。
模型细节
字词混合Embedding
单纯的字向量难以表达语义信息,而词向量有语音信息,但随之有很多切词问题需要解决,比如如何切准确;文章提出一种自行设计的字词混合方式,在多个任务中均取得了有效的提升,具体做法如下:
首先以字为单位的文本序列,经过Embedding后得到字向量序列;然后将文本分词,通过预训练好的模型来提取对应的词向量,为了得到字向量对齐到词向量序列,我们可将每个词重复“词的字数”那么多次;得到对齐的词向量序列后,我们将词向量序列经过一个矩阵变换到跟字向量一样的维度,并将两者相加。流程图如下:
字词混合Embedding方式图示
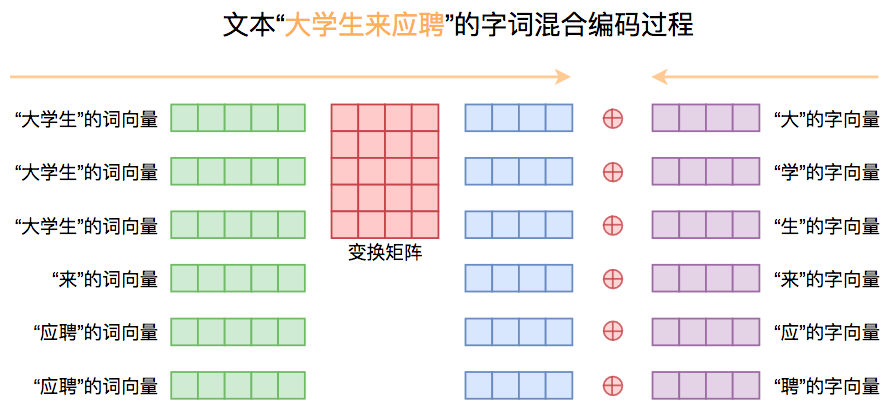
实现上,文章使用pyhanlp作为分词工具,训练了一个Word2Vec模型(Skip Gram + 负采样),而字向量则使用随机初始化的字Embedding层,在模型训练过程中,固定Word2Vec词向量不变,只优化变换矩阵和字向量,从另一个角度看也可以认为是我们是通过字向量和变换矩阵对Word2Vec的词向量进行微调。这样一来,我们既融合了预训练词向量模型所带来的先验语义信息,又保留了字向量的灵活性
Position Embedding
模型主要使用CNN+Attention进行编码,所以编码出的向量位置信息并不敏感,信息抽取中,往往s在于开头,o在s附近,加入一个有效的位置编码信息是有用的;
具体做法是设定一个最大长度为512,然后全零初始化一个新的Embedding层(维度和字向量一样),传入位置ID后输出对应的Position Embedding,并把这个Position Embedding加到前面的字词混合Embedding中,作为完整的Embedding结果,传入到下述DGCNN中。
模型另一处用到了Position Embedding是在编码s的时候,采样得到的s经过BiLSTM进行编码后,得到一个固定大小的向量,然后我们将它复制拼接到原来的编码序列中,作为预测o、p的条件之一。不过考虑到o更可能是s附近的词,所以笔者并非直接统一复制,而是复制同时还加上了当前位置相对于s所谓位置的“相对位置向量”(如果对此描述还感觉模糊,请直接阅读源码),它跟开头的输入共用同一个Embedding层。
DGCNN
这部分接受另起一篇介绍
知识蒸馏
该部分内容是作者在实验阶段的处理手法,基于任务不同数据不同,笔者只单纯对知识蒸馏做一总结,在实际任务中,我们训练集往往有一定的缺陷以及不规范,因此可以使用类似知识蒸馏的方式来重新整理训练集,改善训练集质量。
具体的,我们通过对原始训练集以交叉验证的方式,得到k个模型,然后利用k个模型对训练集进行预测,得到关于训练集的k份预测结果,如果某个样本同时在k份预测结果中但没有在训练集中标注,那么可以对此进行标注,同样的,某个样本在k份预测中都没有出现,但标注了,那么可以对此标注删除,这样以增一减之后训练集就会完善很多,这种方式也在我们实际各个任务中可以使用。
参考文献
https://kexue.fm/archives/6671




