-
三步骤
特征工程
- 常用的特征主要是词袋特征,复杂的特征词性标签、名词短语和树核
特征选择
- 特征选择旨在删除噪音特征,常用的就是移除法
- 信息增益、L1正则
分类器
- 机器学习方面主要有逻辑回归、朴素贝叶斯、支持向量机 —– 数据稀疏性问题
- 深度学习和表征学习为解决数据稀疏问题
RCNN
- 在我们的模型中,当学习单词表示时,我们应用递归结构来尽可能多地捕获上下文信息,与传统的基于窗口的神经网络相比,这可以引入相当少的噪声。
- 还使用了一个最大池层,它自动判断哪些单词在文本分类中起关键作用,以捕获文本中的关键成分。
- 双向递归神经网络来捕捉上下文。
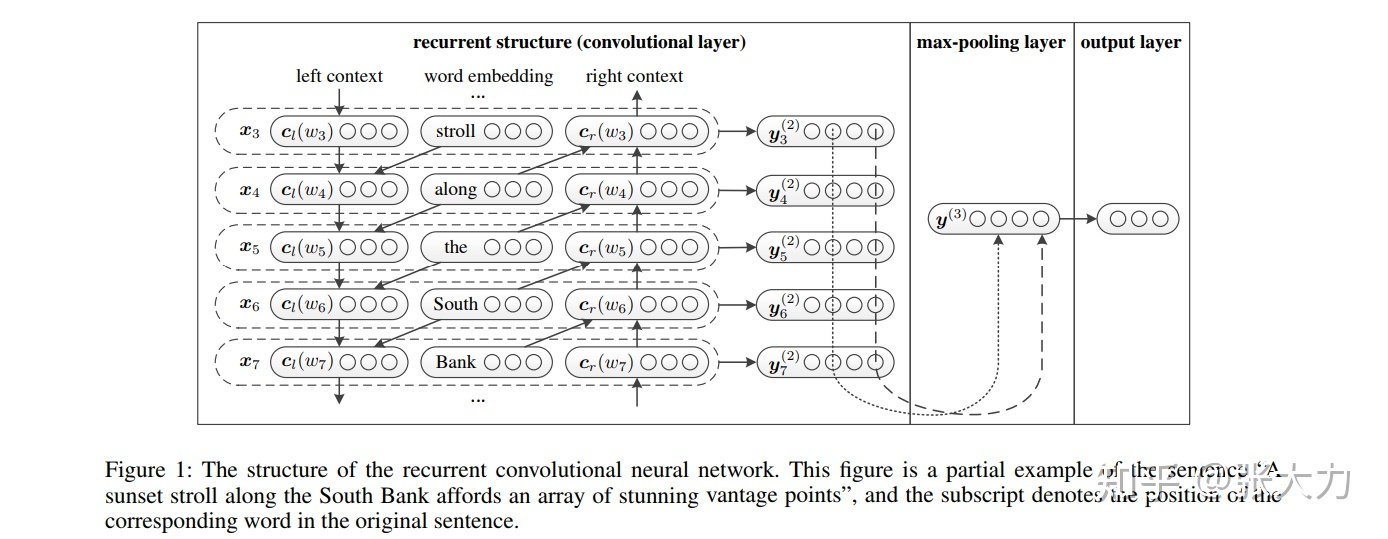
- $c_l(w_i)$用公式一计算,其中$c_l(w_{i-1})$是当前 word 的左侧的 context,$e(w_{i-1})$是单词的嵌入,稠密向量
- TextCNN比较类似,都是把文本表示为一个嵌入矩阵,再进行卷积操作。不同的是TextCNN中的文本嵌入矩阵每一行只是文本中一个词的向量表示,而在RCNN中,文本嵌入矩阵的每一行是当前词的词向量以及上下文嵌入表示的拼接
HAN
GCN
- 提出了一种新的文本分类图形神经网络方法。据我们所知,这是第一次将整个语料库建模为异构图,并利用图神经网络联合学习单词和文档嵌入的研究。
- 在几个基准数据集上的结果表明,我们的方法优于现有的文本分类方法,不使用预先训练的单词嵌入或外部知识。我们的方法还自动学习预测单词和文档嵌入。
输入特征矩阵X=I:one-hot 图边计算方式 word-document:tf-idf word-word:PMI-为了利用全局词共现信息,我们对语料库中的所有文档使用固定大小的滑动窗口来收集共现统计。 A_ij计算方式如下: PMI(i, j); i, j are words, PMI(i, j) > 0 TF-IDF_ij; i is document, j is word 1; i = j 0; otherwise不直接用$D^{-1}A$而选用$D^{-1/2}AD^{-1/2}$,是因为$D^{-1}A$的结果不是对称矩阵,这个大家动手算一下就知道了。虽然两者结果不相同,但是$D^{-1/2}AD^{-1/2}$已经做到了近似的归一化,而且保持了矩阵的对称性,我想这就是选用对称归一化的拉普拉斯矩阵的原因链接,属于拉普拉斯对称归一化链接。
损失函数
交叉熵损失
KL距离常用来度量两个分布之间的距离,其具有如下形式其中p是真实分布,q是拟合分布,H(p)是p的熵,为常数。因此 度量了p和q之间的距离,叫做交叉熵损失。
优化方法
数据优化
- 训练集合和测试集合部分特征抽取方式不一致
- 最后的结果过于依赖某一特征
- 优化方法
- 在全连接层 增加dropout层,设置神经元随机失活的比例为0.3,即keep_rate= 0.7
- 在数据预处理的时候,随机去掉10%的A特征
- 泛化能力较差
- 优化方法
- 增加槽位抽取:针对部分query, 增加槽位抽取的处理,比如将英文统一用
表示,模型见到的都是一样的,不存在缺乏泛化能力的问题. 瓶颈在于槽位抽取的准确率。
- 增加槽位抽取:针对部分query, 增加槽位抽取的处理,比如将英文统一用
- 缺乏先验知识
模型优化
- embedding_dim长度
- 在全连接层增加dropout层
文本分类
 | 阅读:次
| 阅读:次




