
seq2seq是一种循环神经网络的变种,包括编码器和解码器两部分,可用于机器翻译、对话系统、自动摘要
常见seq2seq结构
seq2seq是一种重要的RNN模型,也称为Encoder-Decoder模型,可以理解为 NMN∗M* 的模型,模型包含两部分,Encoder部分编码序列的信息,将任意长度的信息编码到一个向量 cc 里,而Decoder部分通过向量 cc 将信息解码,并输出序列,常见的结构如下几种:
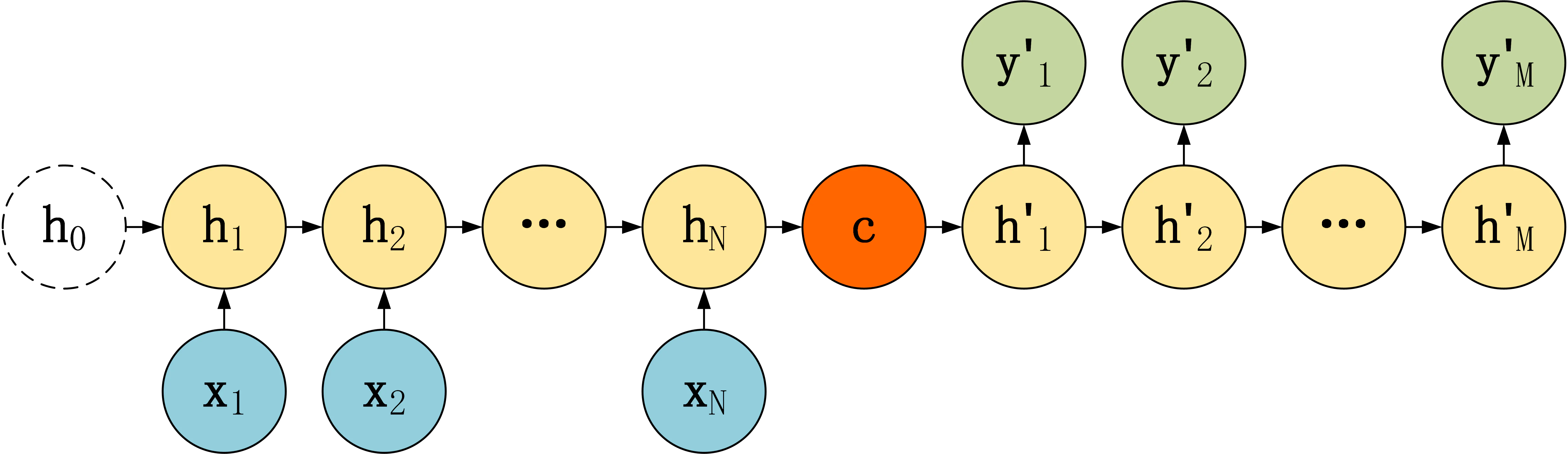
第一种 seq2seq结构
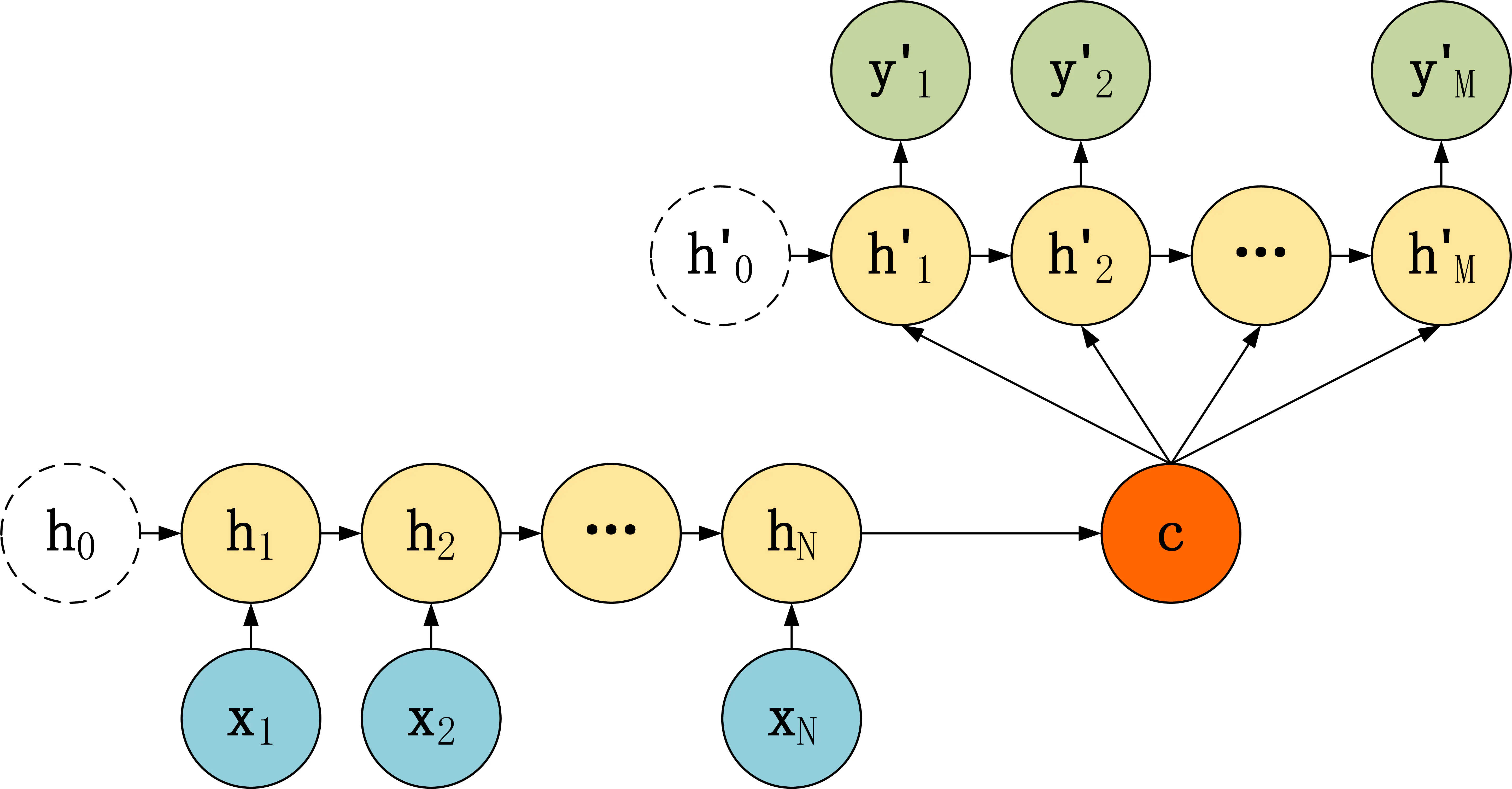
第二种 seq2seq结构
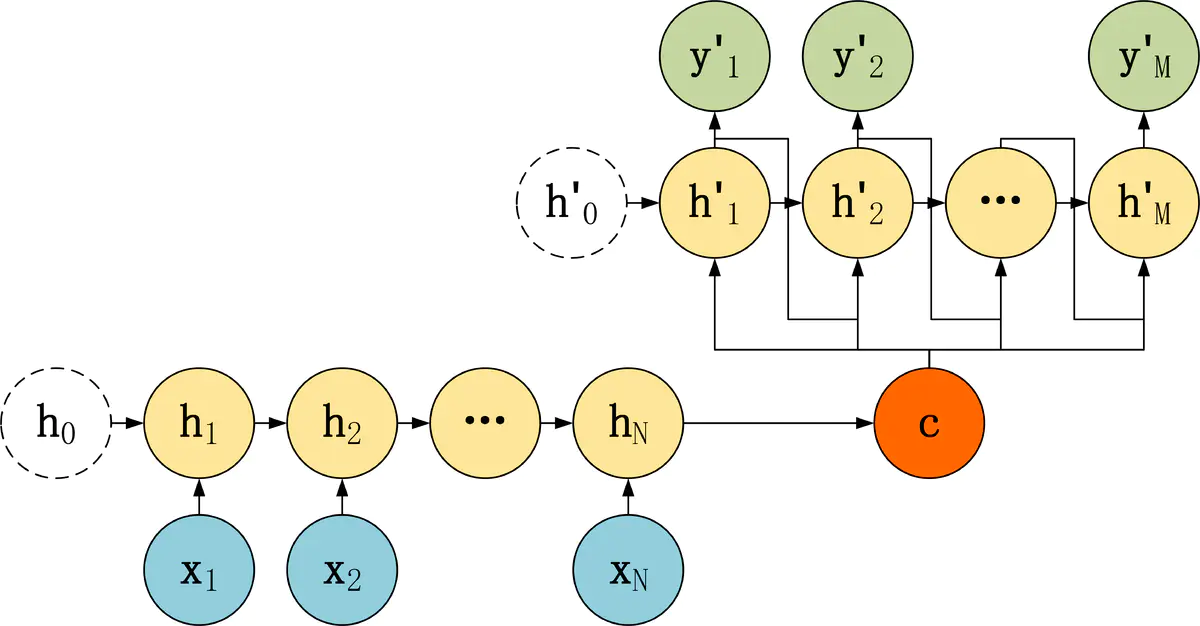
第三种 seq2seq结构
Encoder
· 这三种模型结构的主要区别在于Decoder上,Encoder是一样的,Encoder部分的RNN通过接受输入 $X$ ,通过RNN编码所有信息到$c$(所有神经元最后的输出,不要中间神经元的输出)。
Decoder
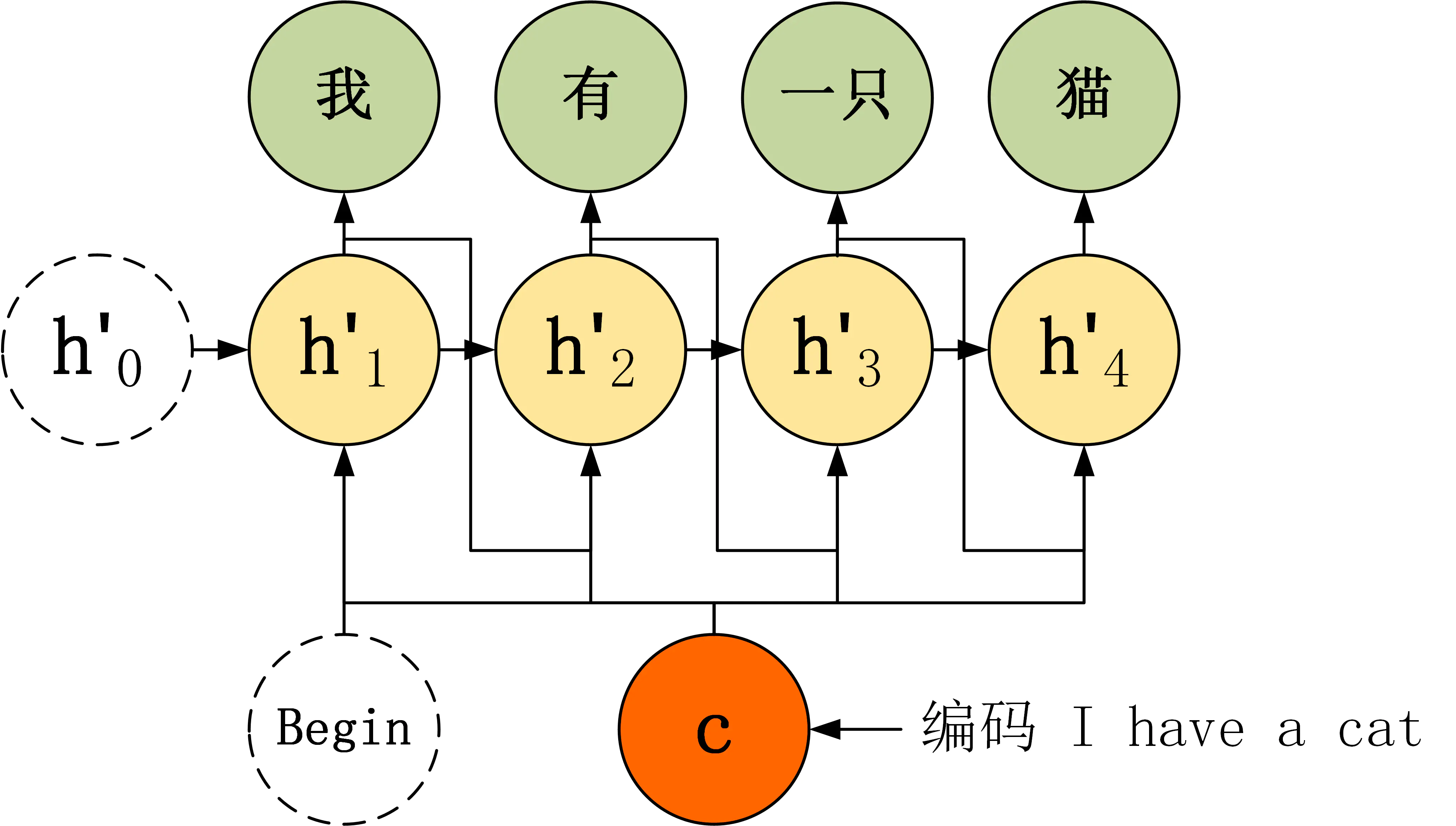
· 第一种Decoder,结构简单,将Encoder编码信息$c$作为Decoder解码隐层的初始输入,后续神经元接受上一神经元的隐层输出状态$h`$
· 第二种Decoder,将Encoder编码信息 $c$作为Decoder解码隐层每个神经元的输入,而不在作为隐层的初始输入;
· 第三种Decoder,再第二种的基础上,每个神经元的输入有了两部分,一部分是Encoder编码信息 $c$,另一部分是Decoder上个神经元的输出,两部分通过不同的权重矩阵来作为当前神经元的输入。
使用trick
Attention
seq2seq模型中,Encoder总是将源句子的信息编码到一个固定长度的上下文 $c$ 中,然后Decoder的过程中 $c$总是不变的,这样就存在几个问题:
- 当源句子较长时,很难用一个定长的向量 cc 表示完所有的信息;
- RNN存在梯度小时的问题,只使用最后一个神经元得到的向量 cc 效果不理想;
- 与人类阅读时的注意力方式不同,人类总是把注意力放在当前句子上
Attention(注意力机制),是一种将模型注意力放在当前翻译单词上的一种机制。例如翻译“I have a cat”,翻译我时注意力在”I“上,翻译猫时注意力在”cat“上。
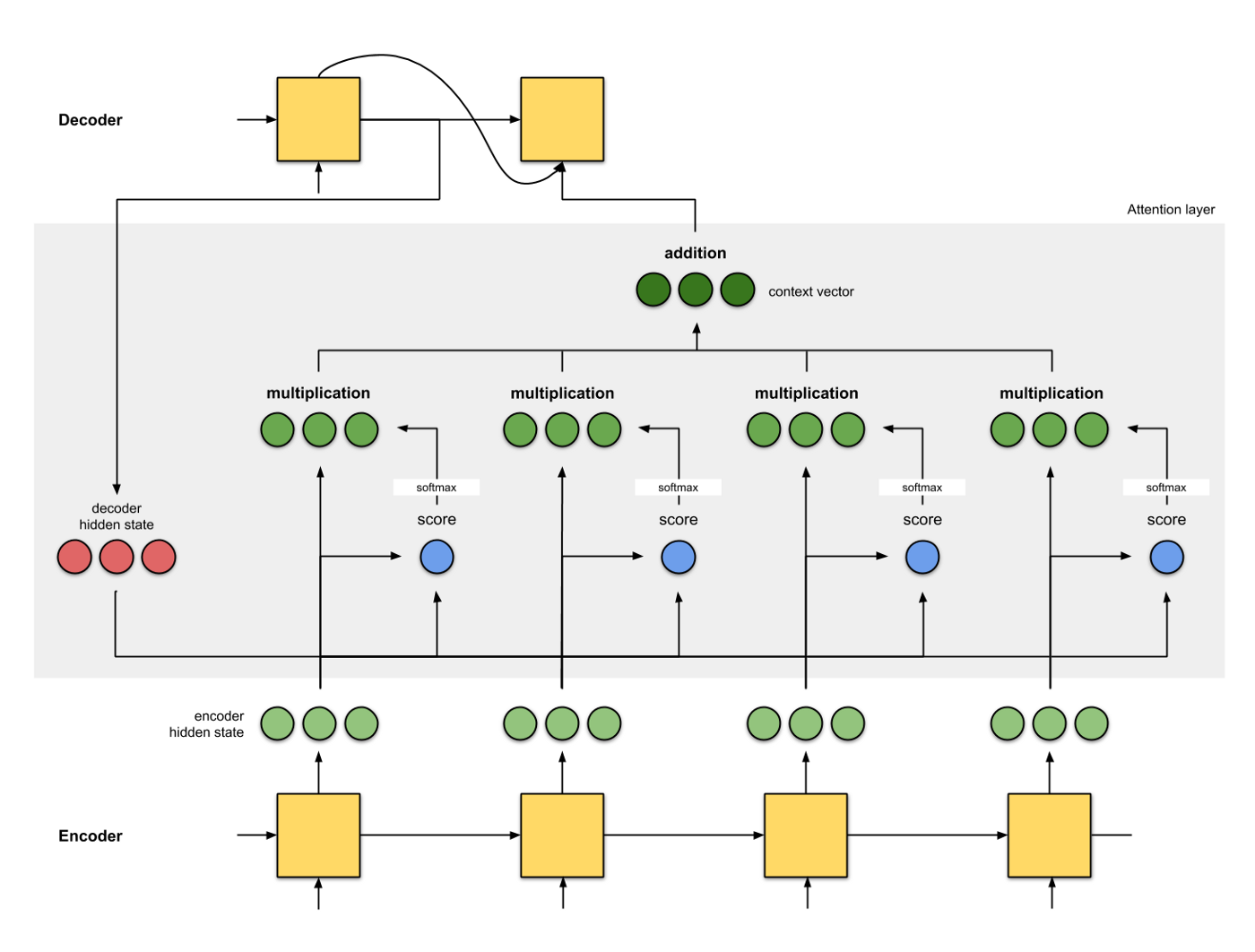
使用Attention后,Decoder的输入就不是固定的上下文向量 $c$了,而是根据当前翻译的信息,计算当前 $c$。
Attention
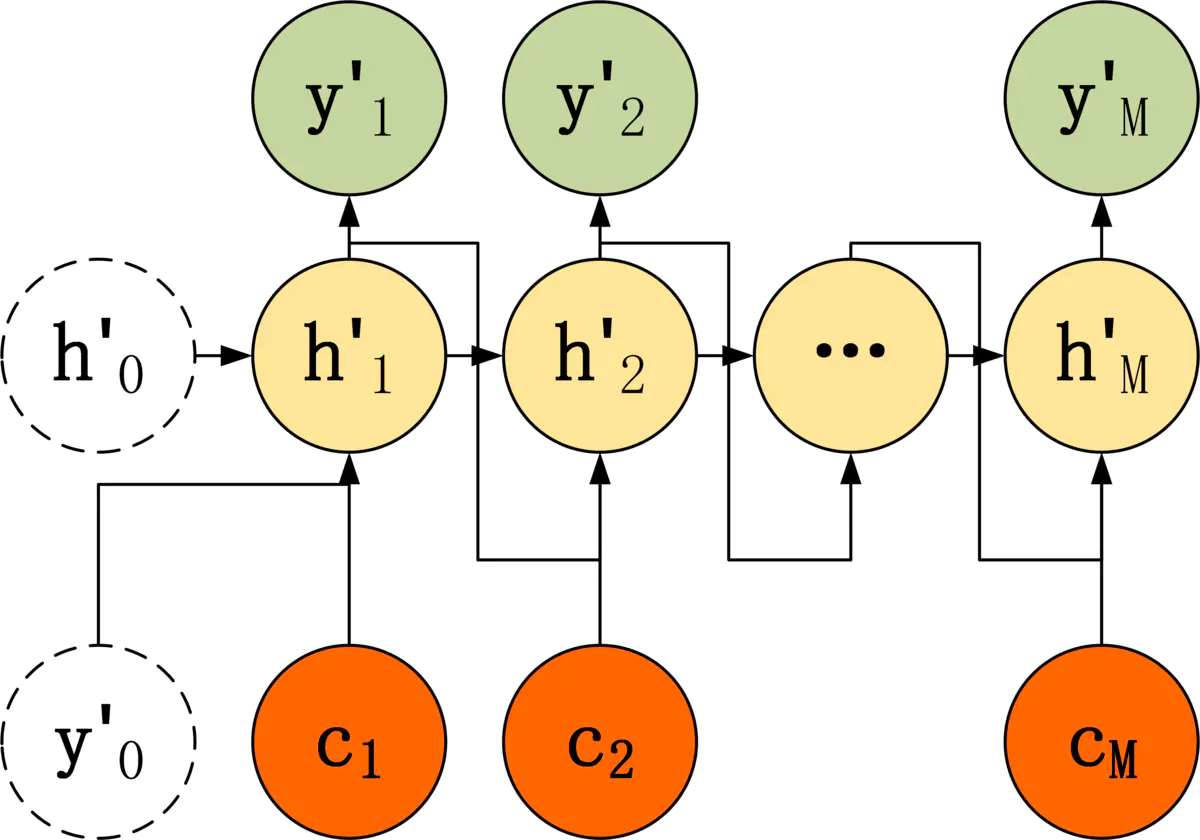
Attention需要保留Encoder每一个神经元的隐藏层向量 $h$ ,然后Decoder的第$t$个神经元要根据上一个神经元的隐藏层向量 $h`_{t-1}$计算当前状态与Encoder每一个神经元的相关性 $e_t$。 $e_t$是一个N维的向量(Encoder神经元个数维N),若$e_t$第$i$维越大,则说明当前节点与Encoder第$i$个神经元的相关性越大。$e_t$的计算方式有很多,即相关性系数的计算函数$a$有很多种:
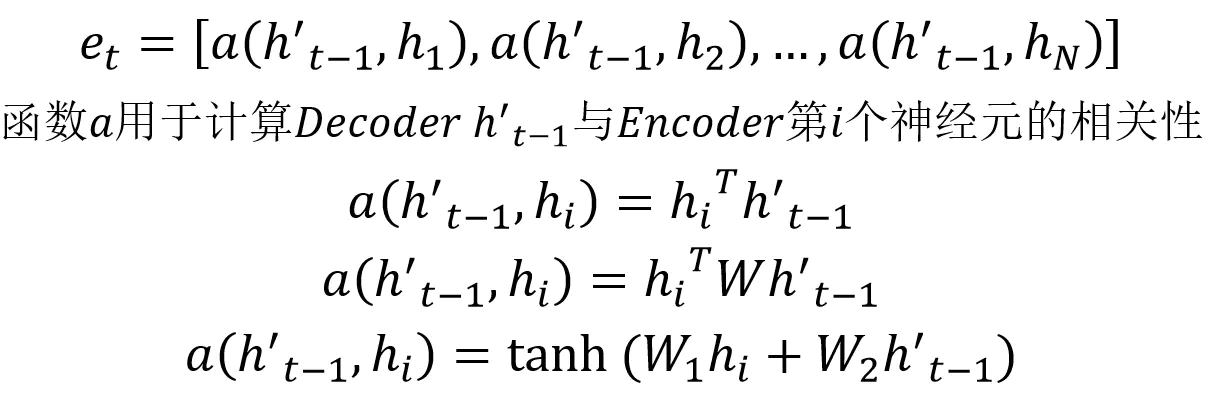
上面得到相关性向量 $e_t$后,需要进行归一化,使用 softmax 归一化。然后用归一化后的系数融合 Encoder 的多个隐藏层向量得到 Decoder 当前神经元的上下文向量 $c_t$:
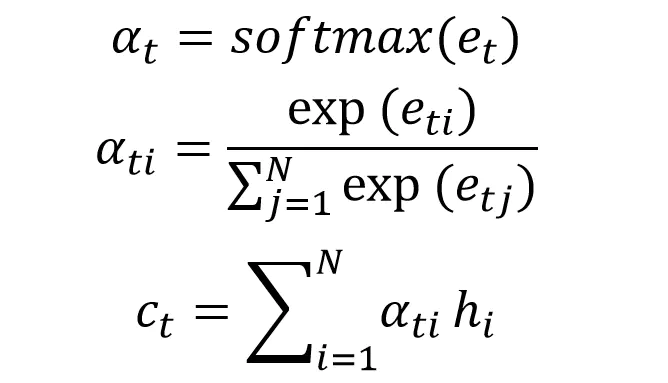
Attention 计算上下文$c$
总体流程图
Teacher Forcing
Teacher Forcing用于训练阶段,主要针对上面第三种Decoder模型来说,第三种Decoder模型输入包含了上一时刻的输出神经元 $y’$,这样就会有个问题,如果上一时刻$y’$是错误的,则后面的神经元也会很容易错误,导致错误传递下去。
Teacher Forcing在一定程度上可以解决这个问题,在训练阶段,Decoder模型每个神经元接受的输入是正确的label,而并未上一时刻神经元的输出,对比如下:
不适用 Teacher Forcing
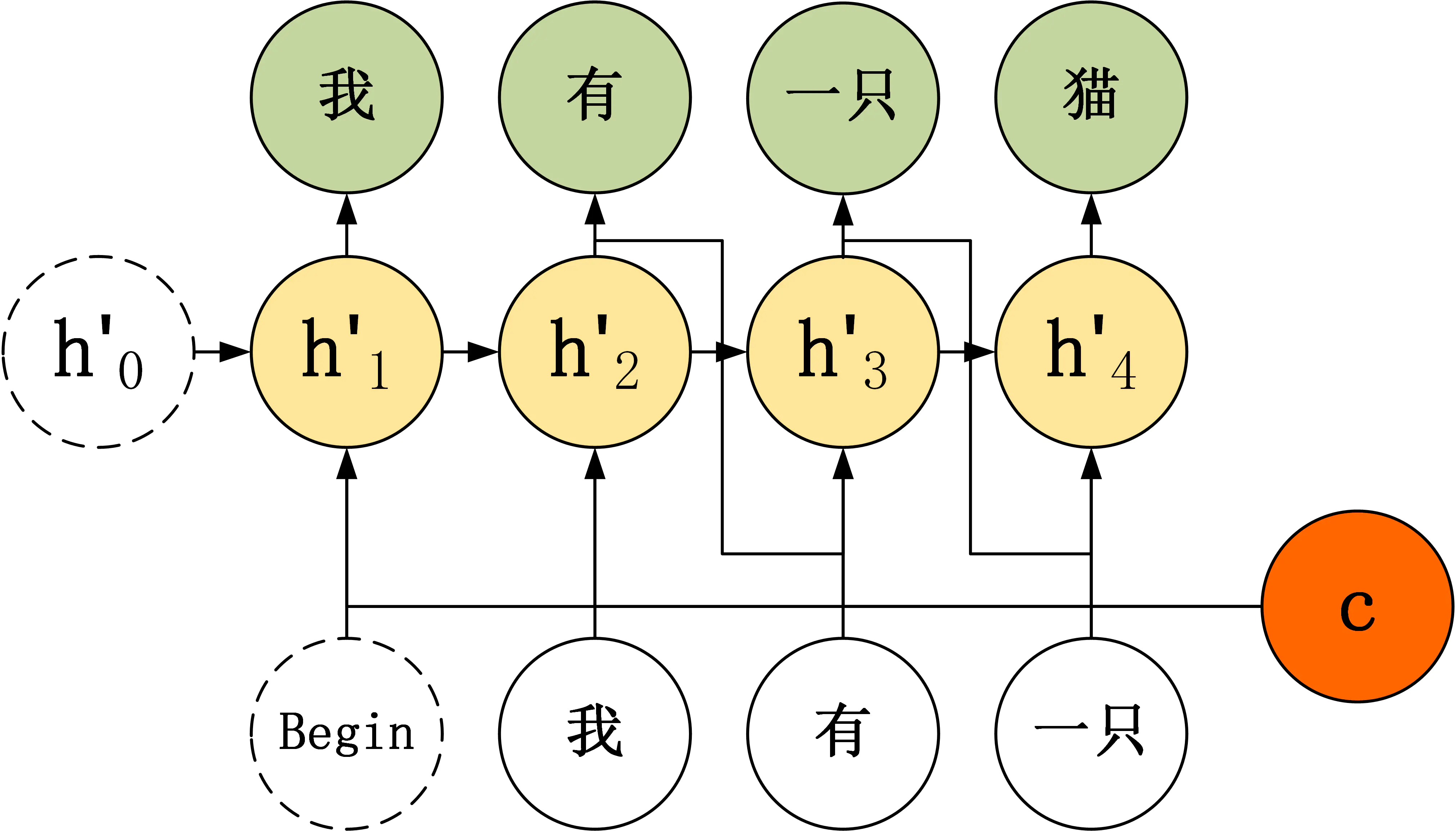
使用Teacher Forcing
Beam Search
Beam Search 方法不用于训练的过程,而是用在测试的。在每一个神经元中,我们都选取当前输出概率值最大的 top k 个输出传递到下一个神经元。下一个神经元分别用这 k 个输出,计算出 L 个单词的概率 (L 为词汇表大小),然后在 kL 个结果中得到 top k 个最大的输出,重复这一步骤。
参考
https://www.jianshu.com/p/80436483b13b
https://towardsdatascience.com/attn-illustrated-attention-5ec4ad276ee3




