
1、什么是Transformer
《Attention is All You Need》是一篇谷歌提出的将attention思想发挥到极致的论文,这篇论文提出一个全新的模型,叫Transformer,抛弃了以往深度学习中的CNN和RNN。包括后来的Bert、GPT等都是基于此构建的,广泛的应用于NLP领域。
2、Transformer结构
2.1 总体结构
Transformer的结构和Attention模型一样,Transformer模型中也采用了encoder-decoder结构。论文中encoder层由6个encoder堆叠在一起,decoder层也一样。
-
encoder,包含两层,一个self-attention层和一个前馈神经网络,self-attention能帮助当前节点仅仅关注当前的词,从而能获得上下文语意
-
decoder,包含encoder提到的两层,但这两层(encoder-decoder)中间还有一层attention层,帮助当前节点获得需要关注的重点内容。
![]()
2.2 Encoder
如图所示,encoder由6个相同的transformer block构成,针对一个block来讲,我们可以看出,首先对其输入进行embedding编码输入,这一步呢类似于word2vec编码,然后通过self-attention送到前馈神经网络,然后到下一个block。
![]()
下面对encoder每个模块进行说明:
-
输入embedding
对输入文本进行向量编码,值得注意的是,编码维度为$\color{blue}{d_{model}}$,encoder的输入和decoder的输入我们进行了权值共享,并且在embedding层每个权重都乘了一个$\color{blue}{\sqrt{d_{model}}}$。
-
位置embedding
Transformer结构由于天然无法感知空间,因此对于文本位置信息并不明确,而对于我们的翻译类任务,顺序信息尤为重要,因此引入位置信息的表达也就迫在眉睫,论文中引入了绝对位置编码,公式如下:
$\color{blue}{PE_{(pos,2i)}=sin(pos/10000^{\frac{2i}{d_{model}}})}$
$\color{blue}{PE_{(pos,2i)}=cos(pos/10000^{\frac{2i}{d_{model}}})}$
其中$\color{blue}{pos}$代表位置,$\color{blue}i$代表向量维度中的index,这样对每个维度都有一个位置编码,偶数位置用正弦编码,奇数位置用余弦编码,最后将位置embedding和输入embedding相加送入block模块中。
-
layer normalization
这里主要说明一下Layer normalization 和Batch normalization的区别,他们都是数据归一化的一种方式,本质都是为了解决梯度消失或者梯度爆炸,主要是将模型中每层偏离的数据拉回归一化数据,这样有利于模型的学习(梯度更新)。区别如图所示:
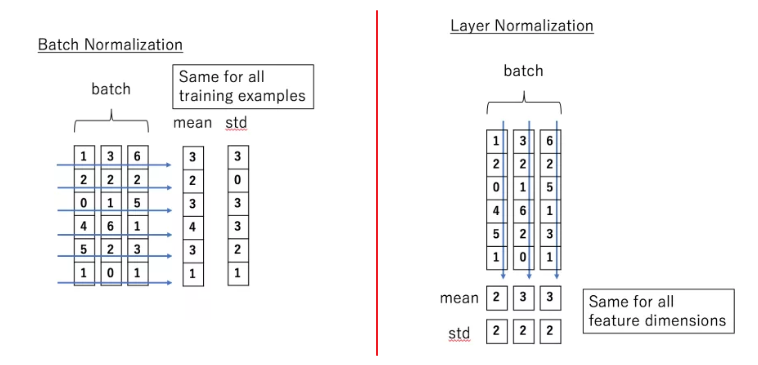
图中可以看出,假设输入为三个字符,每个字符的embedding为6维,那么Batch Normalization是在特征维度进行归一化,而Layer Normalization不同的是在seq也就是图中的batch方向归一化,既对每个字符进行归一化。
(小声bb:图中的batch当作sequence理解,纵向当作每个word的embedding理解,理解二维后再提升到三维理解(带上batch))
2.3 Decoder
decoder和encoder结构大同小异,基本一致,也是对输入做了embedding和位置编码,可以参照encoder,不同之处在于decoder中用到了mask attention,这是较为关键的一点,下面我们对论文提到的三种attention进行说明。
2.4 Attention
- self attention
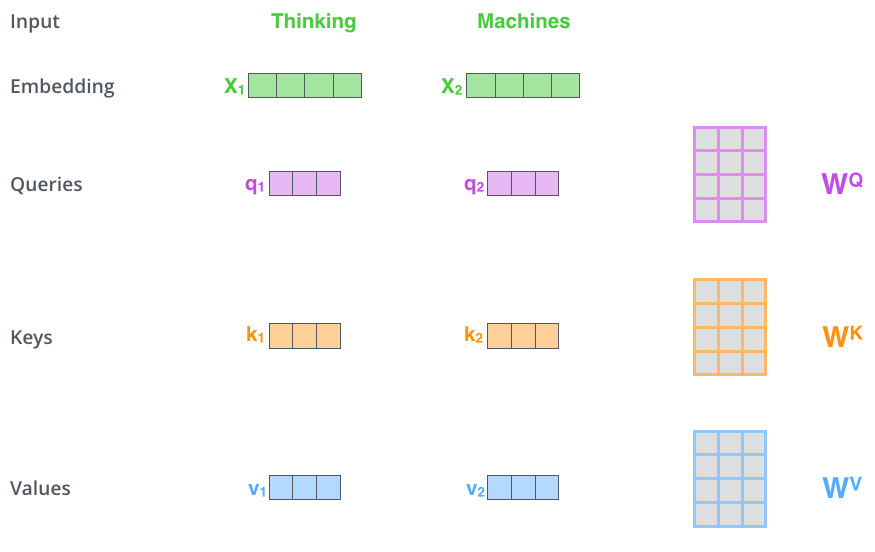
$\color{yellow}{self-attention}$再论文中用于encoder阶段,既每个block模块中对输入进行了$\color{yellow}{self-attention}$,也叫自注意力机制,自注意力机制输入的$\color{blue}{query、key、value}$是相同的,简单来讲,论文中的输入为(None,512),copy为三份,对每一份都用不同的权重矩阵($\color{blue}{W^q、W^k、W^v\in R^{64\times 512}}$),如图所示:
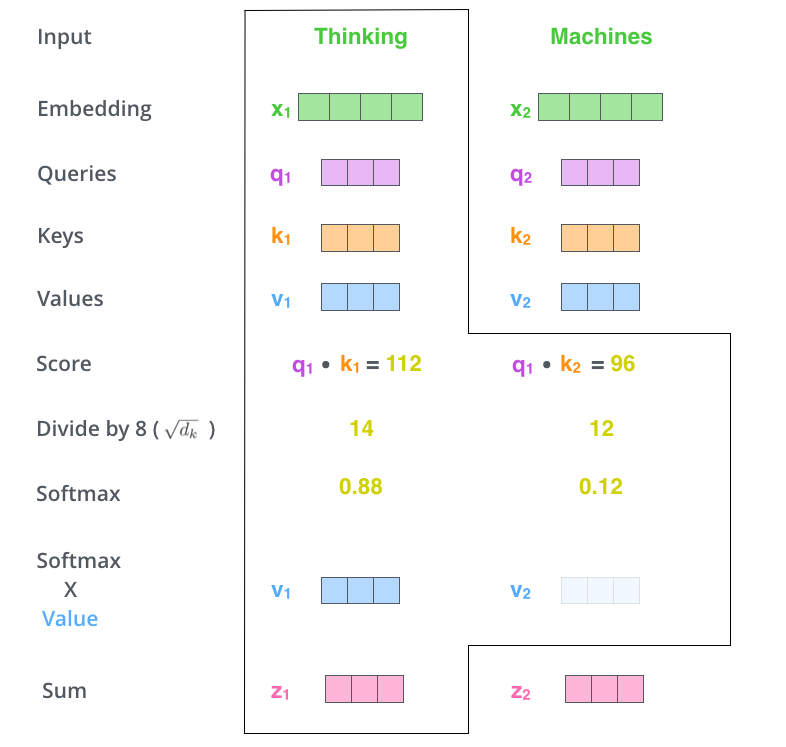
对于$\color{yellow}{self-attention}$来讲,就是要对当前query的词计算对每个词的注意力权重,这个计算由query和key计算得来,计算方式如下,对$\color{blue}{q_1}$来讲,分别计算每个k的Score,论文中提到,对于$\color{blue}{q}$和$\color{blue}{k}$的点乘结果除以一个8($\color{blue}{\sqrt{64}}$),最后做一个softmax,就得到当前q对每个q的注意力分值,对应分值再乘以value向量,然后相加,便得到当前节点的self attention的值。
实际计算中,为了提升效率,q、k、v都为矩阵,计算公式如下:$\color{blue}{Attention(K,Q,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V}$。论文中也把这种方式叫做$\color{yellow}{Scaled Dot-Product Attention}$。
- attention
解码器和编码器之间也用到attention,我们暂叫做普通attention,就是相当于把$\color{yellow}{self-attention}$的query向量变为了decoder中的输入编码,encoder的输出向量作为key、value向量。计算方式同上。
- mask attention
$\color{yellow}{mask-attention}$用于解码器中,由于再解码的过程中,实际上我们并不知道下文会出现什么,而天然的attention会自动学习到后面的信息,这对于实际预测来讲并不公平,因此采用了$\color{yellow}{mask-attention}$,故名思意,就是对当前节点我们通过mask的方式不让attention看到后面的信息,transformer中具体用到了两种mask,一种是$\color{yellow}{padding-mask}$,这部分再$\color{yellow}{self-attention}$中用到,一个是$\color{yellow}{sequence-mask}$,这部分再解码器中用到,具体做法如下:
- padding mask
$\color{yellow}{padding-mask}$是因为模型接受到的输入长度不同,为了便于计算我们通常要padding到相同的长度,这就会有一些短的会补0,而这些是没有意义的,因此再计算attention的时候我们需要把这部分无用的剔除。具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过 softmax,这些位置的概率就会接近0!而我们的$\color{yellow}{padding-mask}$实际上是一个张量,每个值都是一个Boolean,值为 false 的地方就是我们要进行处理的地方。
- sequence mask
$\color{yellow}{sequence-mask}$是为了解码的时候不看到未来的信息,具体做法就是我们构造一个上三角全为0的的矩阵作用到序列上,这样我们再解码计算的时候就不会看到但前节点以后的信息了。
2.5 Multi-head Attention
原论文中说到进行Multi-head Attention的原因是将模型分为多个头,形成多个子空间,可以让模型去关注不同方面的信息,最后再将各个方面的信息综合起来。其实直观上也可以想到,如果自己设计这样的一个模型,必然也不会只做一次attention,多次attention综合的结果至少能够起到增强模型的作用,也可以类比CNN中同时使用多个卷积核的作用,直观上讲,多头的注意力有助于网络捕捉到更丰富的特征/信息。
3、Transformer相比于RNN/LSTM,有什么优势?为什么?
1、Transformer 相比RNN/LSTM并行计算的能力更好,序列信息由于要等信息的传递,所以并行度不高。
2、Transformer 相比RNN/LSTM特征提取能力更强,但不代表可以完全取代RNN/LSTM,任何模型都有其特定的使用场景。




