
Bert全称Bidirectional Encoder Representations from Transformers,再多项NLP任务中引起了轰动,其关键技术创新在于用双向Transformer模型,区别于之前从左向右和从右向左拼接,并添加了MLM的新技术。下面将详细介绍。
背景
计算机视觉领域,通过对大规模数据进行网络训练,然后迁移学习进行微调适用于新的任务,去的很好的效果。近年来,这样的任务也用于许多自然语言任务。在此之前比如ELMo、GPT等。
前人工作
elmo
- 后续使用,根据任务构造结构
gpt
- 后续使用,单向模型
- cloze task, 借鉴了mask model
创新点
- GPT的局限性,单向的,限制了任务的类型,比如情感分类等
- MLM(token) 、 NSP(句子)
工作
- 非监督的特征方法
- 非监督的微调方法
- 迁移学习
- 细节
- 预训练
- 微调
- 模型架构:transformer
- 模型参数
- 切词:wordpiece
- 本意是为了减少词汇表,对一些低频词通过拆分表达,这么做的好处是通过拆分的方式对低频词做了相对较好的表达,相比直接用oov或者低频词表示来说,能学到更多的信息。
- mask 概率
- 具体来说,文章作者在一句话中随机选择 15% 的词汇用于预测。对于在原句中被抹去的词汇, 80% 情况下采用一个特殊符号 [MASK] 替换, 10% 情况下采用一个任意词替换,剩余 10% 情况下保持原词汇不变。这么做的主要原因是:在后续微调任务中语句中并不会出现 [MASK] 标记,而且这么做的另一个好处是:预测一个词汇时,模型并不知道输入对应位置的词汇是否为正确的词汇( 10% 概率),这就迫使模型更多地依赖于上下文信息去预测词汇,并且赋予了模型一定的纠错能力。上述提到了这样做的一个缺点,其实这样做还有另外一个缺点,就是每批次数据中只有 15% 的标记被预测,这意味着模型可能需要更多的预训练步骤来收敛。
- 在 BERT 中训练语言模型是通过预测输入中随机选择的 15% 的标记来完成的。这些标记的预处理如下——80% 被替换为“[MASK]”标记,10% 被替换为随机单词,10% 使用原始单词。导致作者选择这种方法的直觉如下(感谢来自 Google 的 Jacob Devlin 的洞察力):
- 如果我们在 100% 的情况下使用 [MASK],该模型不一定会为非屏蔽词生成良好的标记表示。非屏蔽词仍然用于上下文,但该模型针对预测屏蔽词进行了优化。
- 如果我们 90% 的时间使用 [MASK],10% 的时间使用随机单词,这将告诉模型观察到的单词永远不会正确。
- 如果我们 90% 的时间使用 [MASK],10% 的时间保持相同的单词,那么模型可以简单地复制非上下文嵌入。
- 没有对这种方法的比率进行消融,它可能在不同的比率下效果更好。此外,模型性能没有通过简单地屏蔽 100% 的选定标记进行测试。
总结
- 双向性
- 生成类工作不方便
- 生成类工作不方便不代表不能用于生成任务,我们可以通过对生成结果进行mask,而模拟出生成效果,具体来说就是生成任务只能看到上文,而不能看到下文,与Bert的任务冲突,但是我们对生成部分用上三角mask,通过这种方式可以保证在生成的过程中只能看到上文,而看不到下文,这样就可以用Bert来做生成任务啦!
工作原理
使用了Transformer,这是一种注意力机制,可以学习文本单词之间的上下文信息。普通的Transformer包含两部分,读取文本输入的编码器和生成的解码器,Bert任务的目标是生成语言模型,因此只需要编码器机制。Transformer介绍$\color{red}{Transformer探索}$。
MLM
将单词序列输入Bert之前,每个序列中15%的单词被替换为[MASK]标记,然后Bert尝试根据非屏蔽的上下文来预测屏蔽的原始词。技术角度来讲需要以下几点:
- 在编码器输出之上添加一个分类层;
- 将输出向量乘以嵌入矩阵,将他们转换为词汇维度;
- 用softmax计算词汇表中每个单词的概率。
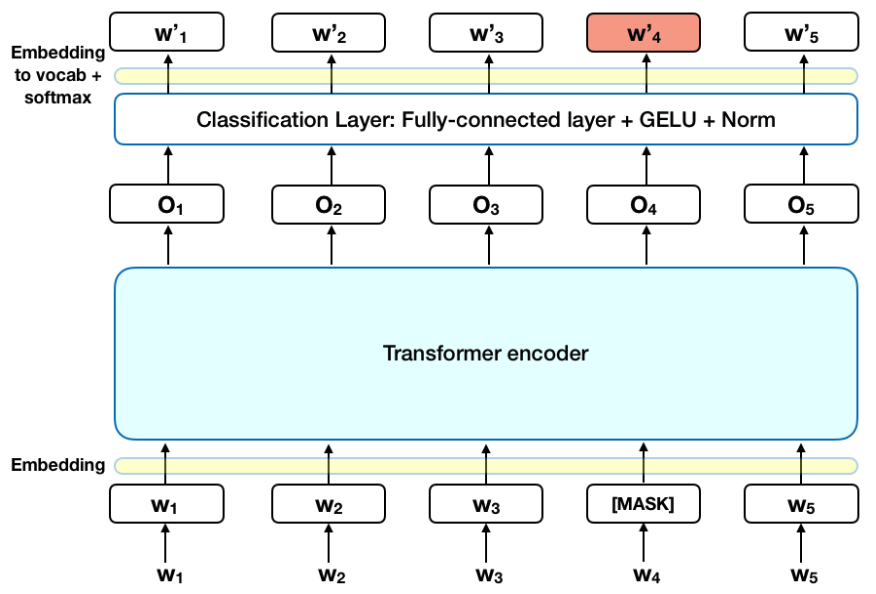
Bert损失函数只考虑掩码值的预测,而忽略非掩码词的预测,因此模型的收敛速度比定向模型慢,这一特征被其增强的上下文感知所抵消。
NSP
在Bert训练过程中,模型接受成对的句子作为输入,并学习预测成对中的第二个句子是否是原始文档中后续句子。在训练过程中,50%的输入是一对,其中第二个句子是原始文档中的后续句子,而另外50%的输入是从语料库中随机选择的一个句子作为第二个句子。
为了帮助模型区分训练中的两个句子,输入在进入模型之前按以下方式处理:
- 在第一个句子的开头插入一个[CLS]标记,在每个句子的末尾插入一个[SEP]标记;
- 表示句子A或句子B的句子嵌入被添加到每个标记中;
- 将位置嵌入添加到每个标记以指示其在序列中的位置。
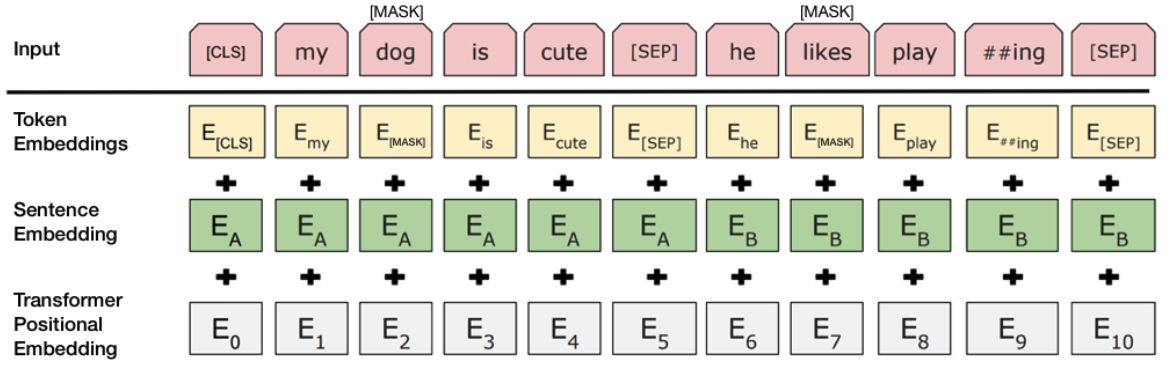
为了预测第二个句子是否确实与第一个句子相关,执行以下步骤:
- 整个输入序列经过Transformer模型
- [CLS]标记的输出使用简单的分类层转换为$\color{blue}{2\times 1}$形状的向量
- 用softmax计算Is Next Sequence的概率
在训练Bert模型时,Masked LM 和 Next Sentence Prediction 是一起训练的,目标是最小化两种策略的组合损失函数。
微调
将Bert用于特定的任务相对简单,可以用于各种各样的语言任务,而只在核心模型中增加一个小层
- 通过在[CLS]标记的Transformer输出顶部添加分类层,完成诸如情感分析之类的分类任务与Next Sentence分类类似;
- 在问答任务(例如SQuAD v1.1)中,模型收到一个关于文本序列的问题,并需要在序列中标记答案,使用Bert,可以通过学习标记答案开始和结束的两个额外向量来训练问答模型;
- 在命名实体识别中,接受一个文本序列,并需要标记文本中出现的各种类型的实体(人、组织、地点等)。使用Bert,可以通过将每个标记的输出向量输入到预测NER标签分类层来训练NER模型。
训练相关
- 模型的大小很重要,即使规模很大。Bert large拥有3.45亿个参数,是同类模型中最大的。他在小规模任务上明显优于Bert base,后者“仅”1.1亿个参数;
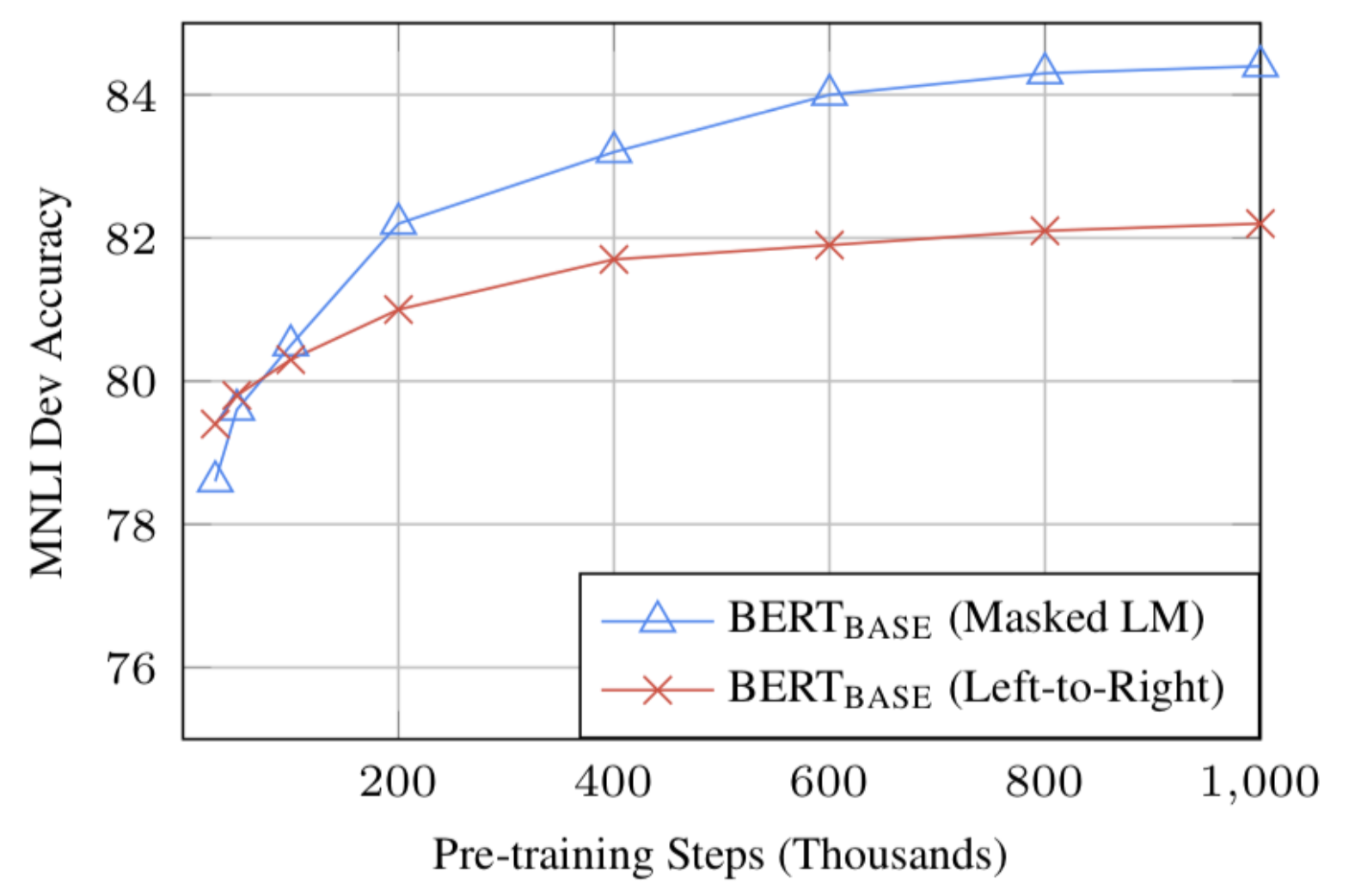
- 有了足够的训练数据,更多的训练步骤==更高的准确度,eg:在MNLI任务上,与具有相同批量大小的500K步相比,Bert base在1M(批量大小为128000字)上训练时的准确度提高了1%;
- Bert的双向方法(MLM)的收敛速度比从左到右的方法慢(因为每批中只有15%的单词被预测),但在少量预训练步骤后,双向训练仍然优于从左到右的训练
参考文献
1、BERT Explained: State of the art language model for NLP




